[Tutorial]: Unreal Engine 5.3 Learning Agents: Learn a sphere to roll using reinforcement learning using C++
Description:
This tutorial aims to get started with the Unreal 5.3 Learning framework using mainly c++.
The C++ code can be found HERE.
Author: Anthony Frezzato.What is reinforment learning:
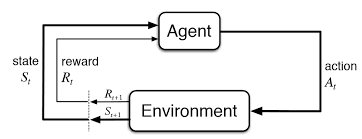
In reinforcement learning we want to train an agent to achieve a specific goal. A policy is trained using a reinforcement process.
In our case, the policy is a neural network that provides the best actions for a given state. During the learning process the policy is trying different actions to discover the behavior we want to achieve.
A reward function informs if the actions chosen is good or not. If yes, the neural network is updated to reinforce this action more frequently. The reward function is a simple scalar value.
This tutorial is based on the Learning to Drive (link) provided by Epic Games except that the agent is a simple sphere simulated by physics.
Create the project:
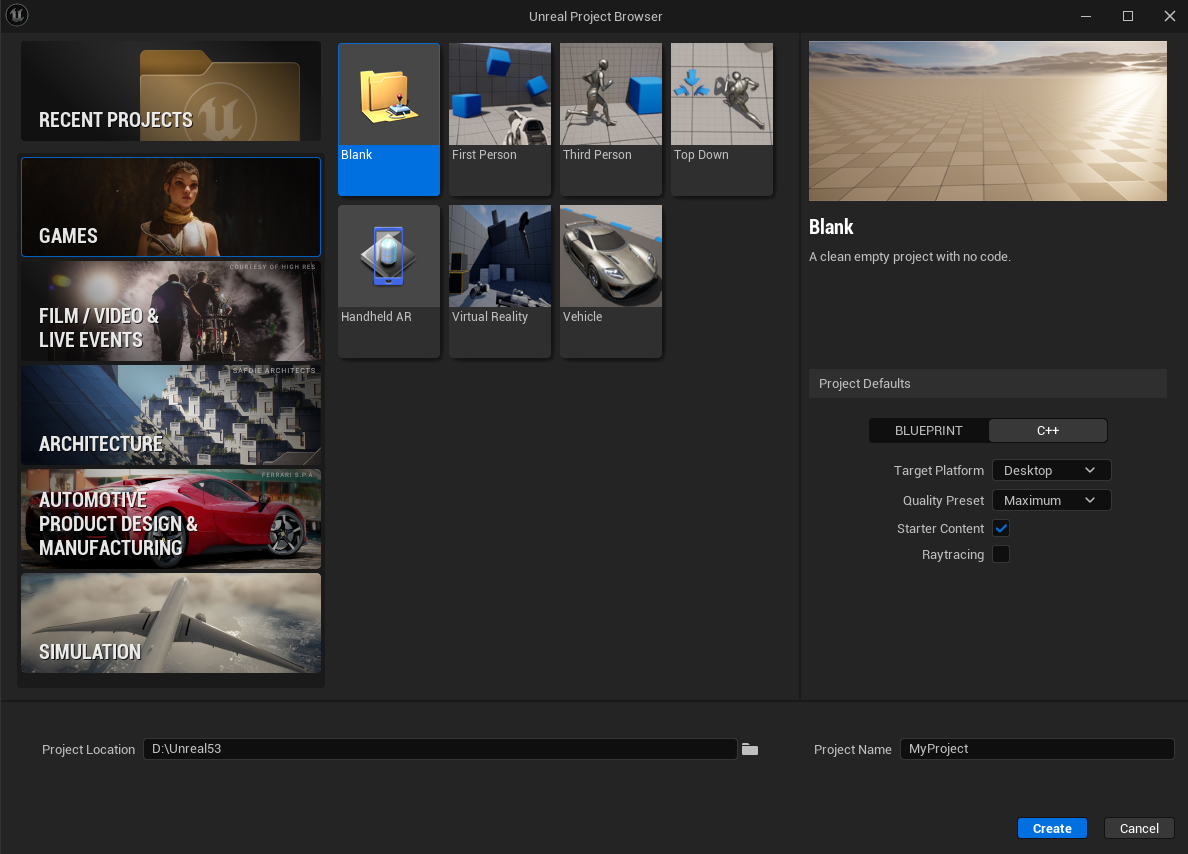
First create a new blank c++ project with the name that you want.
We need to enable the Learning Agents plugin. In the top navigation menu, click Edit then Plugins. Search for “Learning Agents” and select the checkbox near the plugin to enable it.

We need to create the pawn that will represent the agent. Our pawn contains a sphere static mesh component with physics enabled.
Create a new the new pawn using Tools -> new c++ class and select pawn.
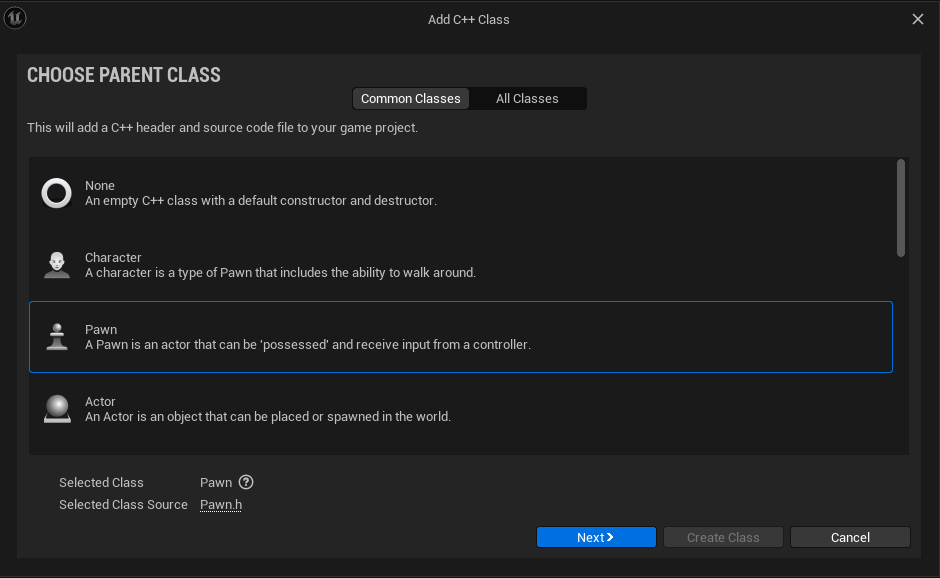
Name it as SpherePawn

Create a new folder named Blueprints inside the content folder.
Create the blueprint based on our new c++ class as follow and save it inside Blueprints folder.
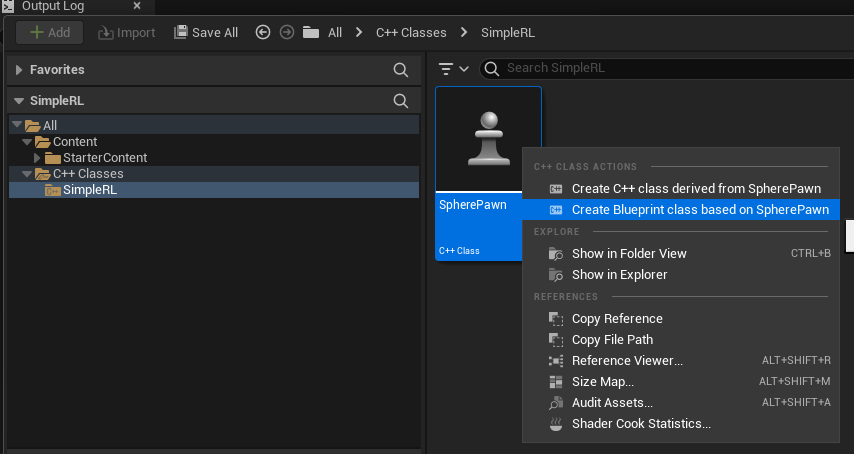
The blueprint will open and add the sphere static mesh as follow.
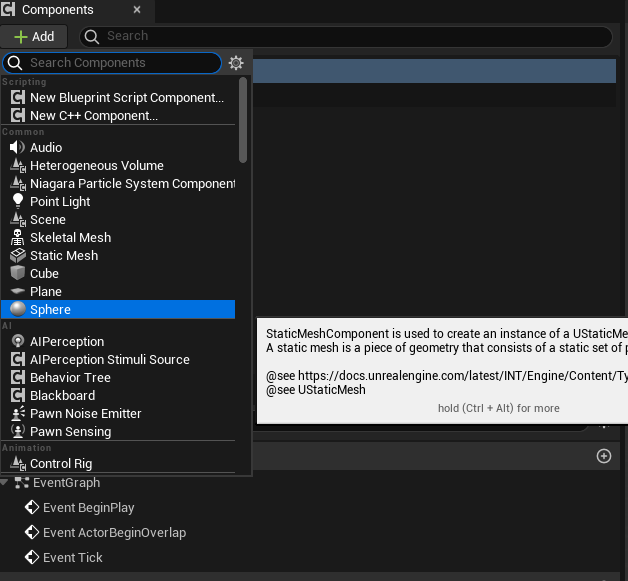
In the details pane, enable Simulate Physics and enable mass with 5kg.
Go to collision preset and change to custom and turn off collision with Pawn and Physics body in order to not collide with other spheres.
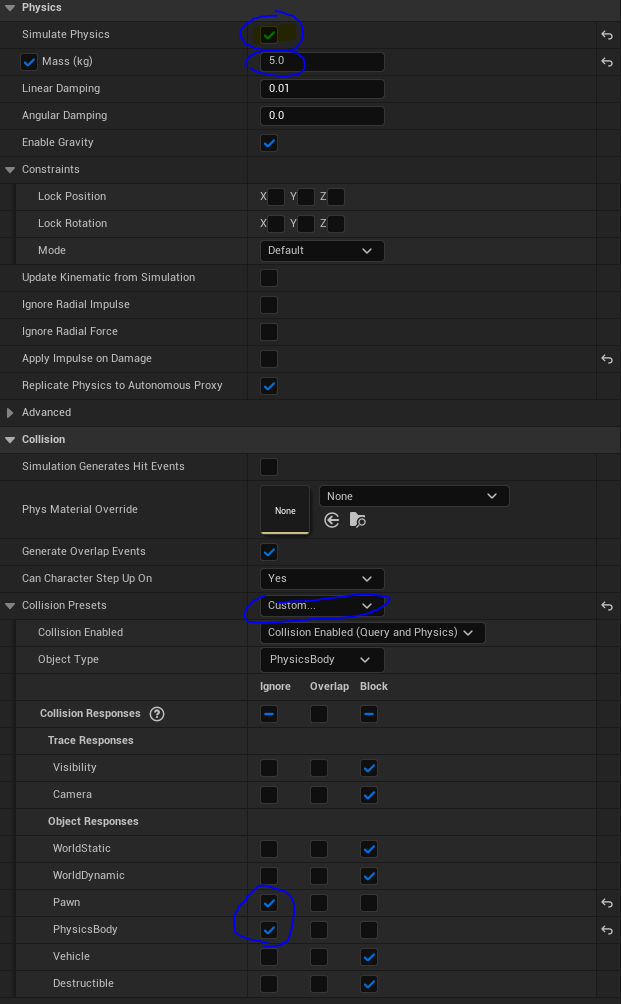
Add a spring arm and a camera attached to it. Adjust the camera a little bit as bellow.
Go to the Event Graph and add the blueprint code in order that the actor follow the static mesh:
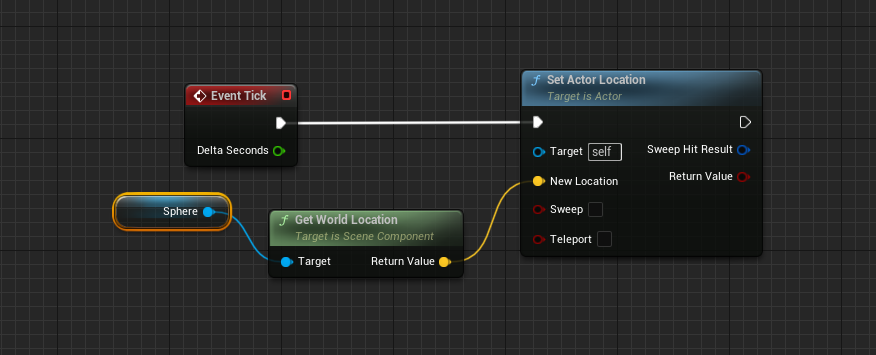
At this point, the blueprint pawn is done, compile and save it.
We need to add actions that the policy will request to move the pawn (MoveX(...) and MoveY(...)).Also, we need to create the speed observation GetSphereVelocity().
We need to implement a function to reset the position of the pawn.
The SpherePawn.h header look like this.
[Code to SpherePawn.h]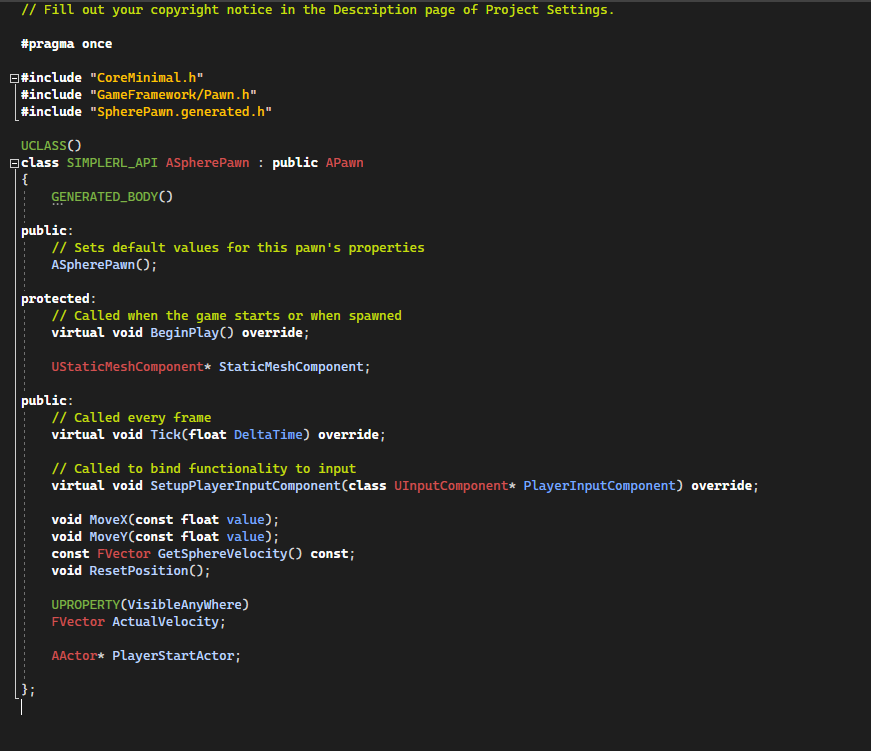
Implement the BeginPlay() as follows, in this function we save a pointer to the StaticMeshComponent and also a pointer to the PlayerStart that will be lately used for the reset position.
[Code to SpherePawn.cpp]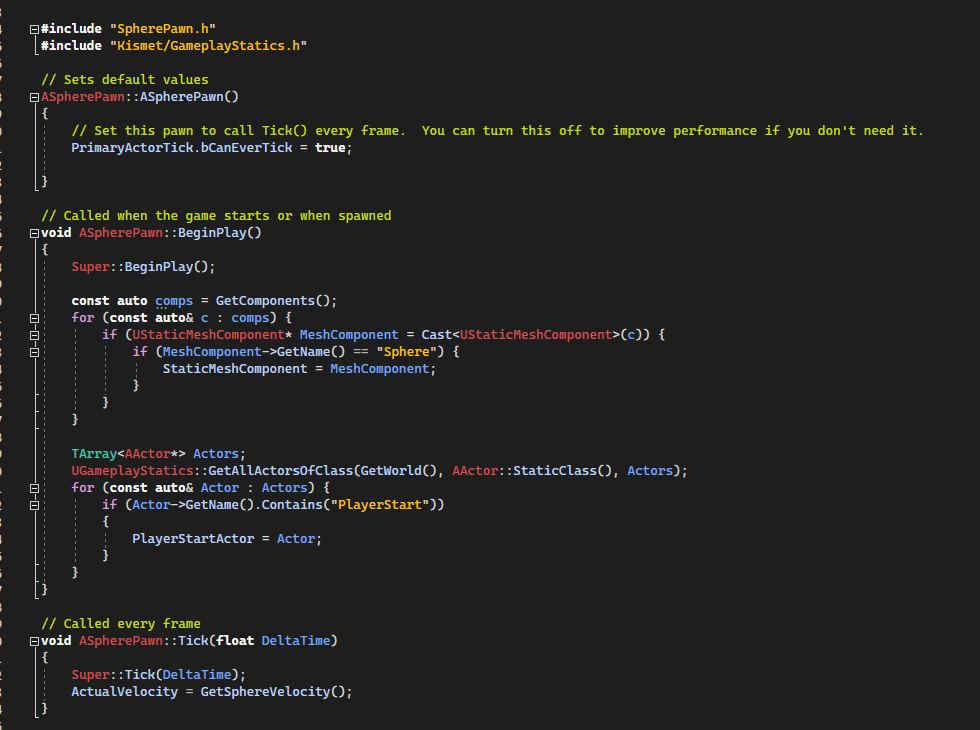
In the Tick(float DeltaTime), we just update a member variable (ActualVelocity) of the current speed for debug purpose.
[Code to SpherePawn.cpp]
We add now the moveX and MoveY that apply a force to move the speed.
GetSphereVelocity() is the current speed of the sphere that will be used as observation.
ResetPosition() Move the component at the PlayerStart position and reset Linear and angular velocity.
[Code to SpherePawn.cpp]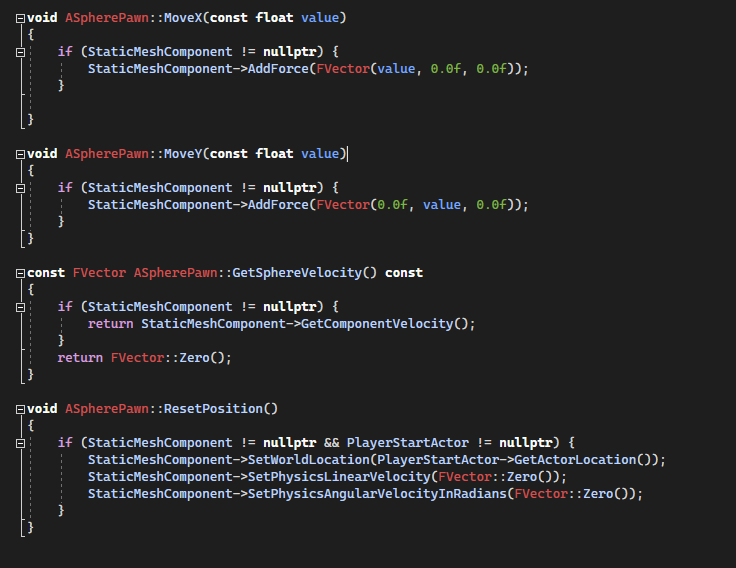
Create Learning Agent Manager
The manager is an actor around which the rest of Learning Agents is built. It acts both as a data structure which stores references to the various agents, as well as a place to specify the learning logic. Multiple agents are handled in a batch for efficient processing. Agents can be any UObject, which means you are unrestricted on what can be an agent. In this example, we will use the SpherePawn as our agent(s). The manager class is extended by a set of manager components which add to the manager’s functionality: the Interactor, Trainer, Recorder, to name a few. We will dive into these components later in this tutorial. (Mulcahy et Holden 2023).
Before adding the manager, open YourProjectName.Builds.cs and add the Public Dependency Module to LearningAgents as follow.
[Code to SimpleRL.Build.cs]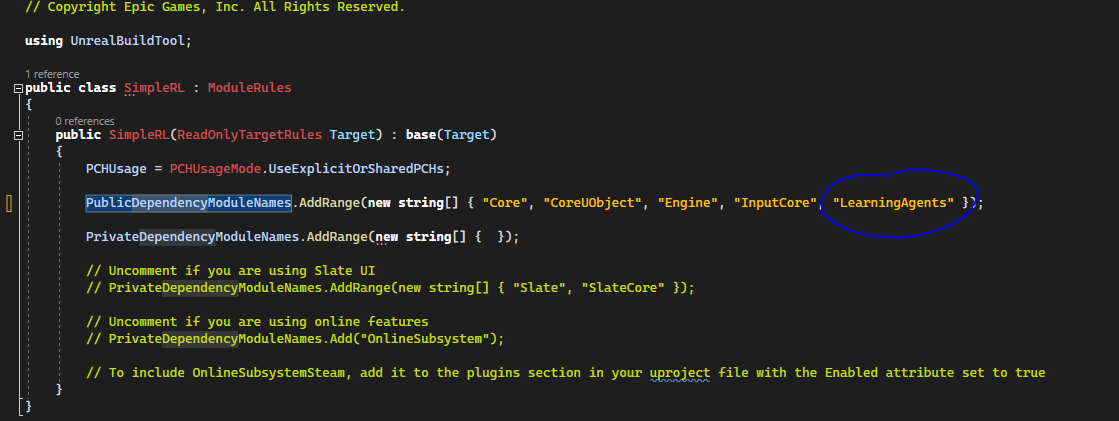
Add a C++ class, search for LearningAgentsManager inside All Classes tab.
Name it as SphereLearningAgentsManager
Because our Manager depends on the interactor and the trainer, create this two classes before implementing the manager.
Add a C++ class, search for LearningAgentsInteractor inside All Classes tab.
Name it as SphereLearningAgentsInteractor
Add a C++ class, search for LearningAgentsTrainer inside All Classes tab.
Name it as SphereLearningAgentsTrainer
At this point we created all necessary c++ class for our project.
Open now SphereLearningAgentsManager.h and the code should look like this:
[Code to SphereLearningAgentsManager.h]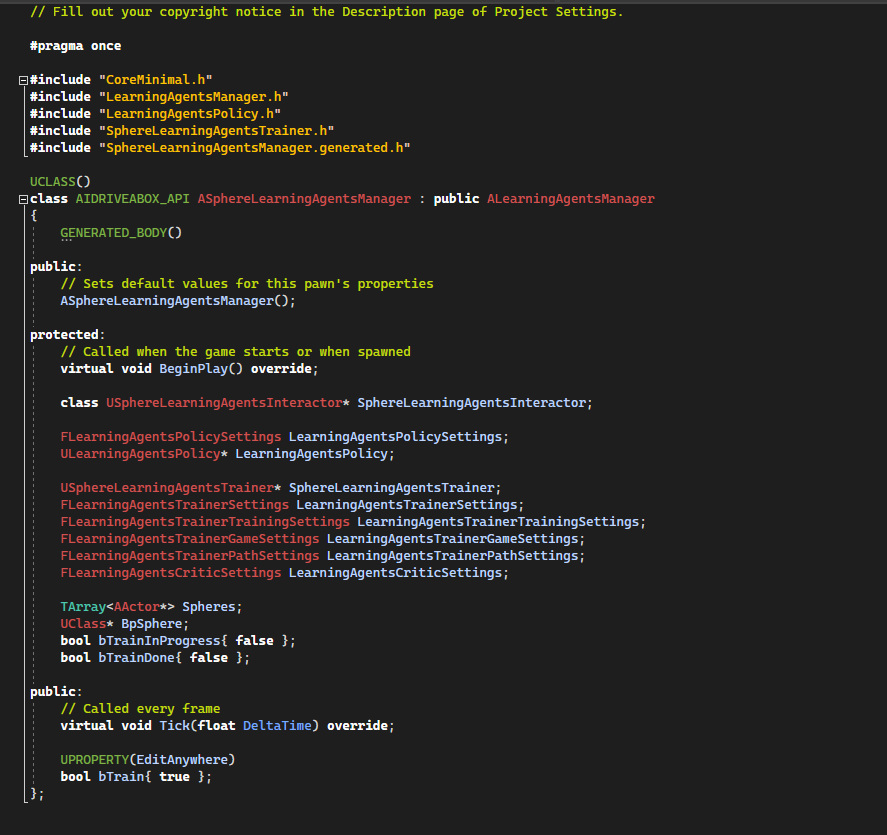
SphereLearningAgentsInteractor will store a pointer to the Interactor that we will add later.
LearningAgentsPolicy variables will store a pointer and parameters to the Policy that we will add later.
SphereLearningAgentsTrainer variables and parameters will store a pointer to the Trainer that we will add later.
Spheres is an array that stores pointers to our Pawn Actors.
bTrainInProgress, bTrainDone is used for tracking the state of the trainning.
The manager constructor search for the BpSpherePawn asset, this will be used to spawn many pawns.
[Code to SphereLearningAgentsManager.cpp]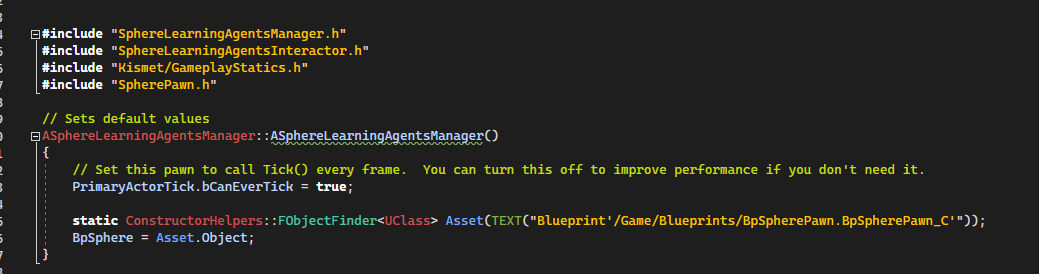
The manager BeginPlay() will spawn 31 Pawns and will store array pointers to the SpherePawns.
We iterate over attached components of the manager to save pointers to the Interactor, the trainer and the policy.
Note that we did not create a c++ class for the policy since we do not need to implement specific logic into it.
Finally, if we found ours components we can setup the interactor, the policy and the trainer.
[Code to SphereLearningAgentsManager.cpp]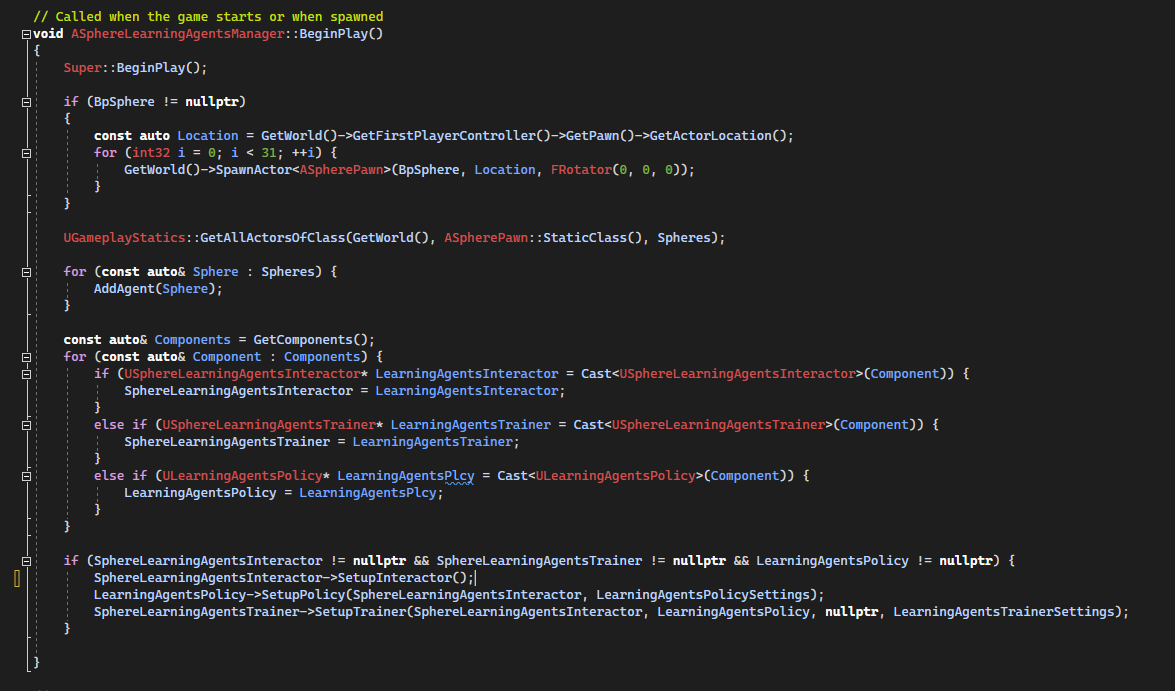
The manager Tick() will perfom a training step.
We begin by training the policy and switch to the final trained policy after completion.
[Code to SphereLearningAgentsManager.cpp]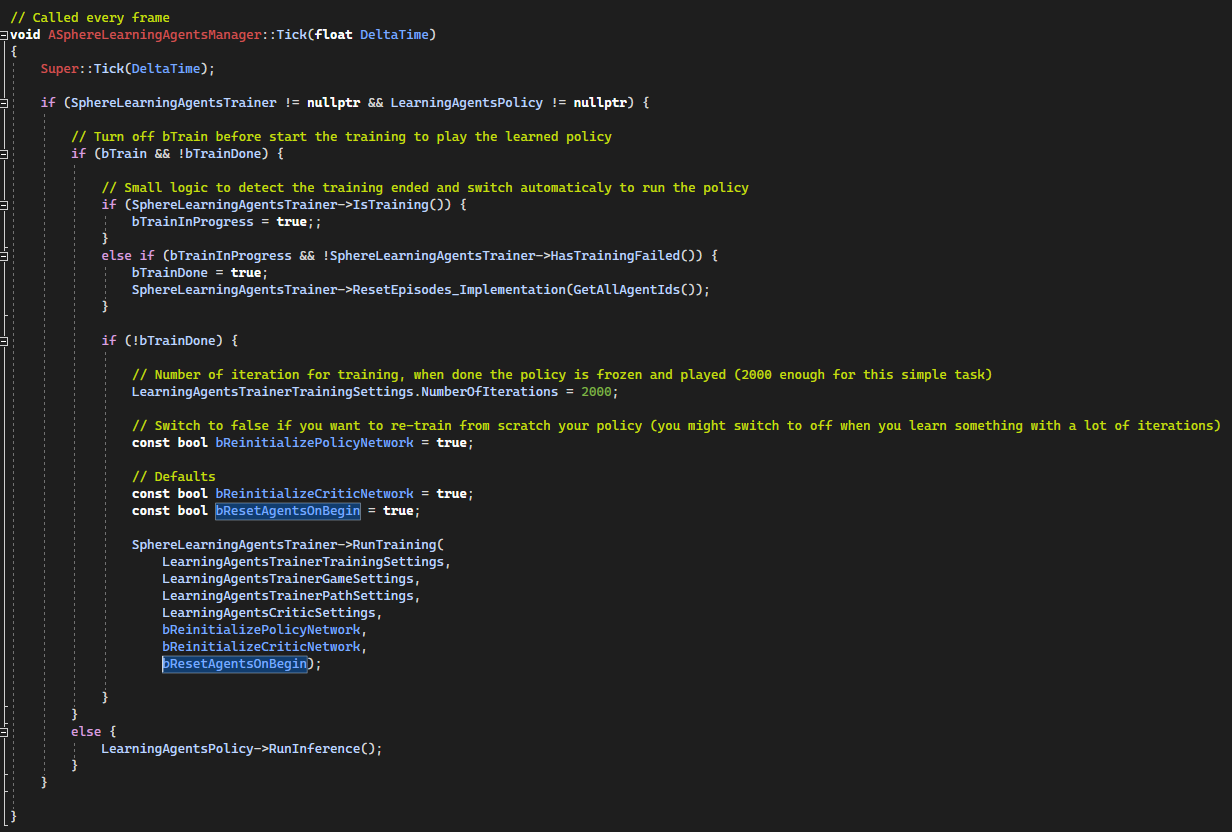
Interactor
The interactor component is responsible for defining how the manager’s agents interact with the world through observations and actions. All agents for a given manager share a common set of observations and actions. The interactor has four main functions we need to implement for our game: SetupObservations, SetObservations, SetupActions, and GetActions. (Mulcahy et Holden 2023)
Open the SphereLearningAgentsInteractor.h
[Code to SphereLearningAgentsInteractor.h]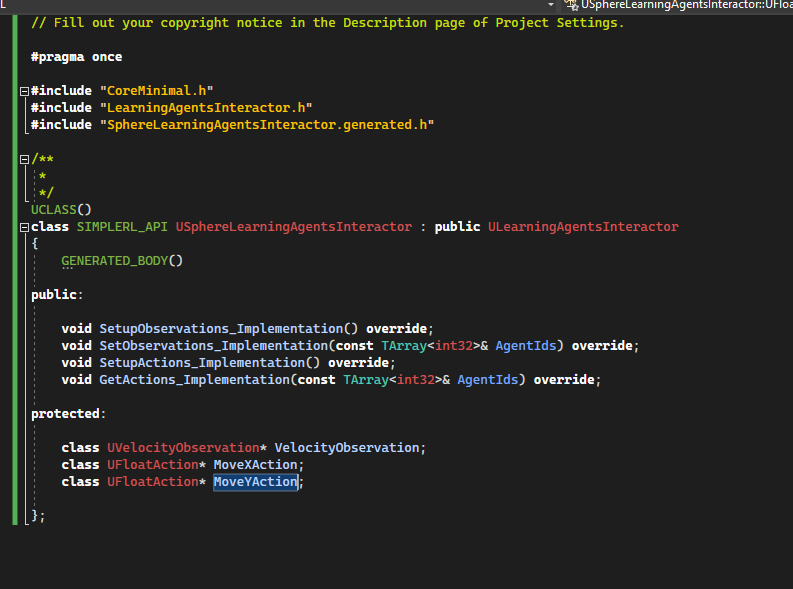
VelocityObservation is an object that will be used to describe the observation of the velocity.
MoveXAction et MoveYAction are the two actions that make move the pawns by the policy.
Interactor Observations
[Code to SphereLearningAgentsInteractor.cpp]

SetupObservations_Implementation() and SetObservations_Implementation are event called by the framework.
SetupObservations_Implementation() tell the framework that we observe a velocity vector, since the target speed is 100, we scale it to 100 to normalize the value.
SetObservations_Implementation update the speed observation by reading the speed of the sphere.
SetupObservations is called once, and SetObservations at every time step.
Interactor Actions
[Code to SphereLearningAgentsInteractor.cpp]
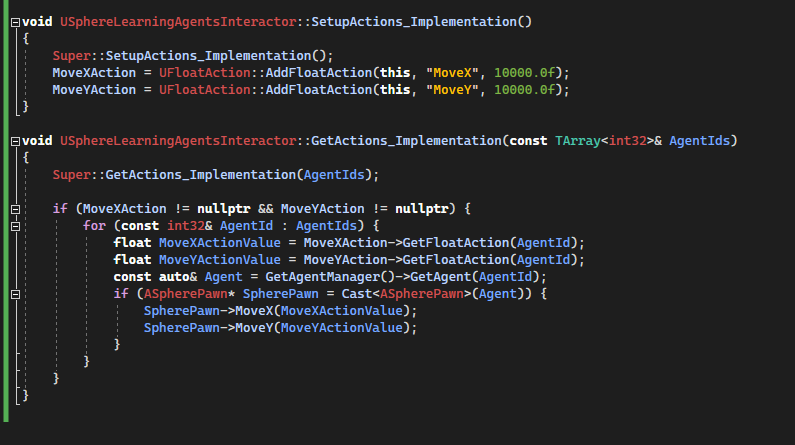
SetupActions_Implementation() and GetActions_Implementation are event called by the framework.
SetupActions_Implementation() tell the framework that we will be the action we will need from the policy.
GetActions_Implementation is used to get the actions generated from the policy that we apply to our pawns.
SetupActions_Implementation() is called once, and GetActions_Implementation at every time step.
TrainerThe trainer is responsible for training the agents to perform the correct actions in the game, given the observations they are seeing. We need to implement two things: rewards and completions. (Mulcahy et Holden 2023)
Open SphereLearningAgentsTrainer.h
[Code to SphereLearningAgentsTrainer.h]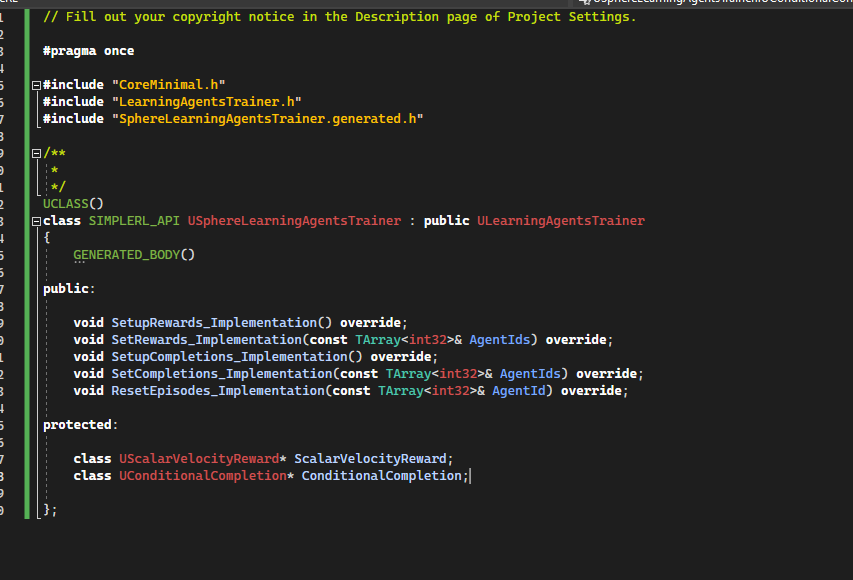
ScalarVelocityReward will be used to represent the reward and ConditionalCompletion the completion (not used in the tutorial)
Trainer reward[Code to SphereLearningAgentsTrainer.cpp]
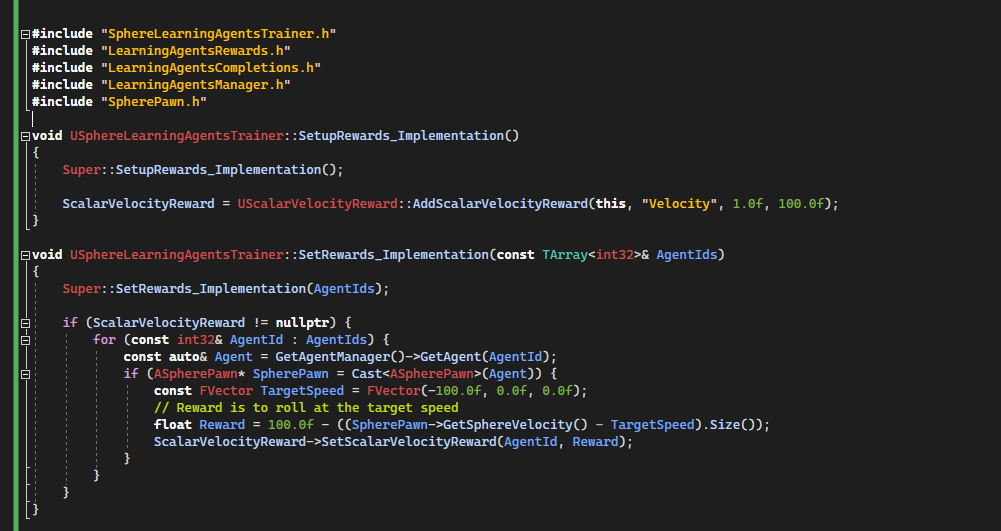
SetupRewards_Implementation() is called by the framework in order to add all the rewards. Here we add just a single scalar reward value to monitor the speed. We scale to 100, because we aims to run at 100 unit/s. We normalize better the reward.
SetRewards_Implementation is called at every time step to update the reward, we implement a simple reward that consist to run at -100 unit/s in X world direction.
Trainer completion[Code to SphereLearningAgentsTrainer.cpp]
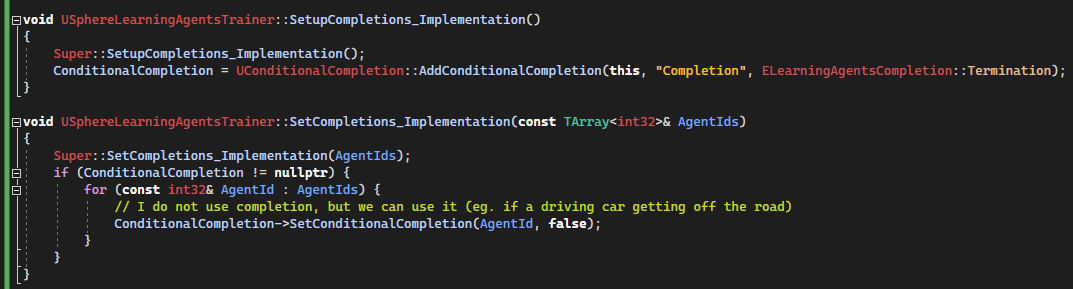
SetupCompletions_Implementation() is called by the framework in order to add a completion. We add a conditional boolean completion, but we don't really need it for this tutorial.
SetCompletions_Implementation is called a every time step to check if the episode should be completed, here we always send false because not really used in this tutorial.
Trainer reset episode[Code to SphereLearningAgentsTrainer.cpp]
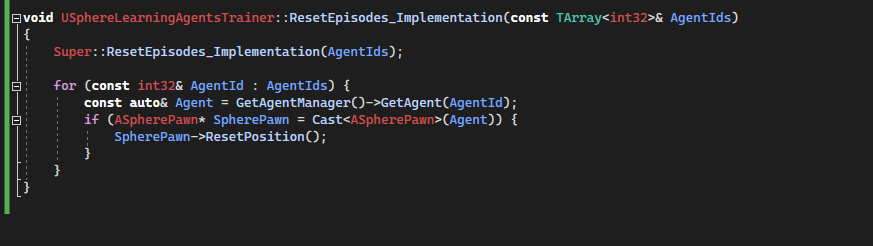
ResetEpisodes_Implementation is called by the framework to indicate that all agents must be reset. Here we iterate through all SpherePawn and reset their positions and speeds.
Create Manager Blueprint and Add components to managerWe need now to create a blueprint based on the SphereLearningAgentsInteractor c++ class, SphereLearningAgentsTrainer c++ class and a simple blueprint for LearningAgentsPolicy.
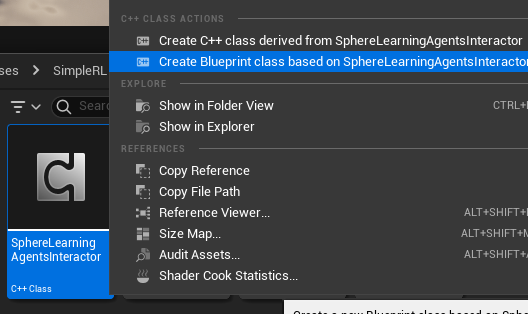
Name it as BpSphereLearningAgentsInteractor, save and close it.
Do same for SphereLearningAgentsTrainer.
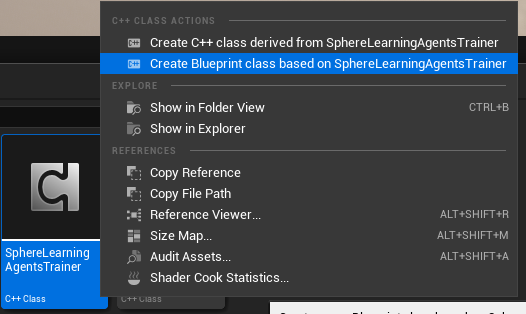
Name it as BpSphereLearningAgentsTrainer, save and close it.
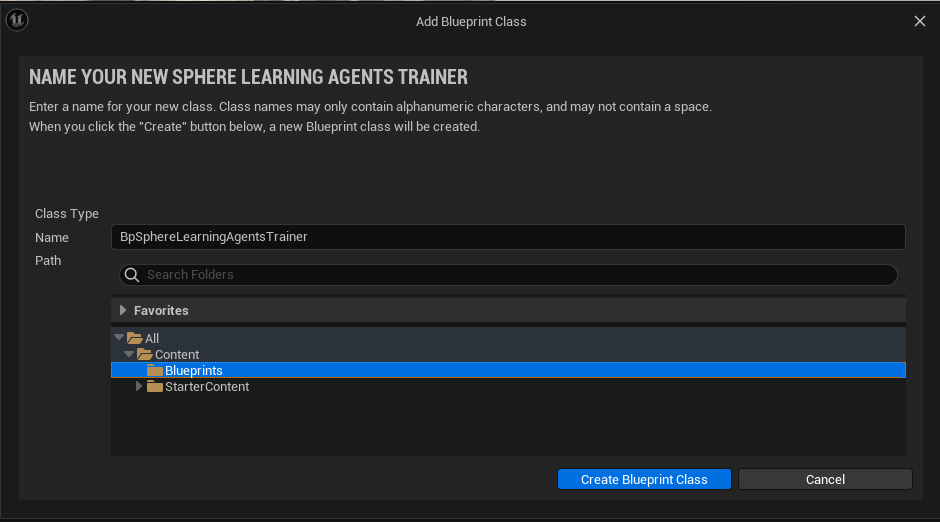
Create a new Blueprint for the LearningAgentsPolicy.
Name it as BpLearningAgentsPolicy and save it.
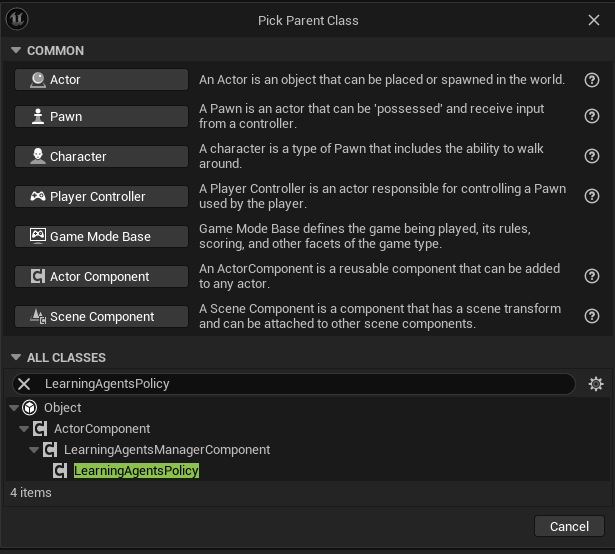
Create the blueprint based on the LearningAgentsManager c++ class.
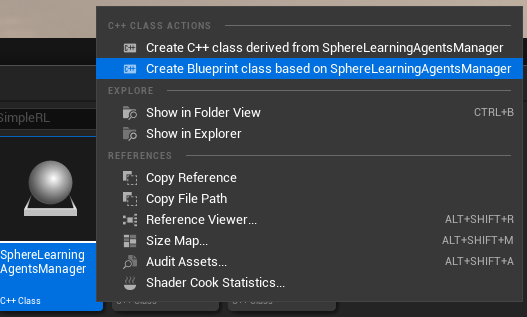
Name it as BpLearningAgentsManager and open it.
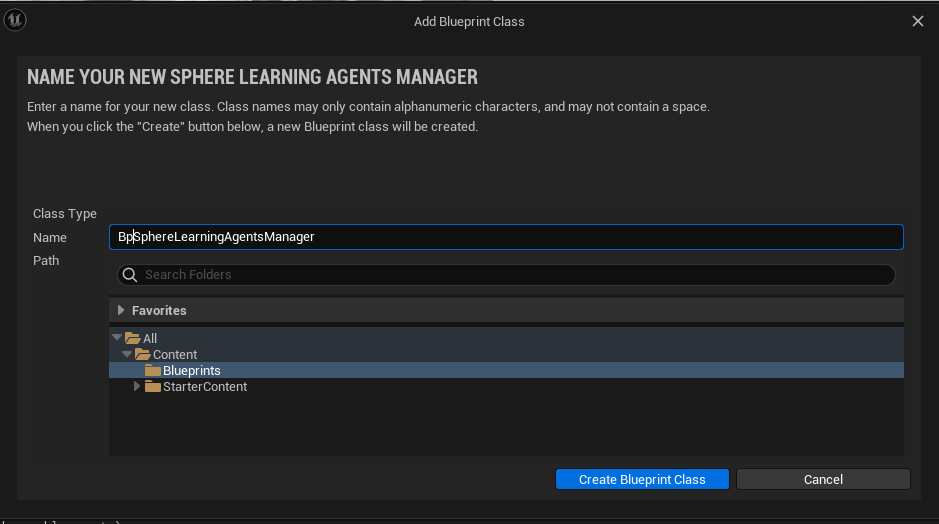
Add components and filter by 'Bp' to find the tree blueprints that we need to add to the manager.
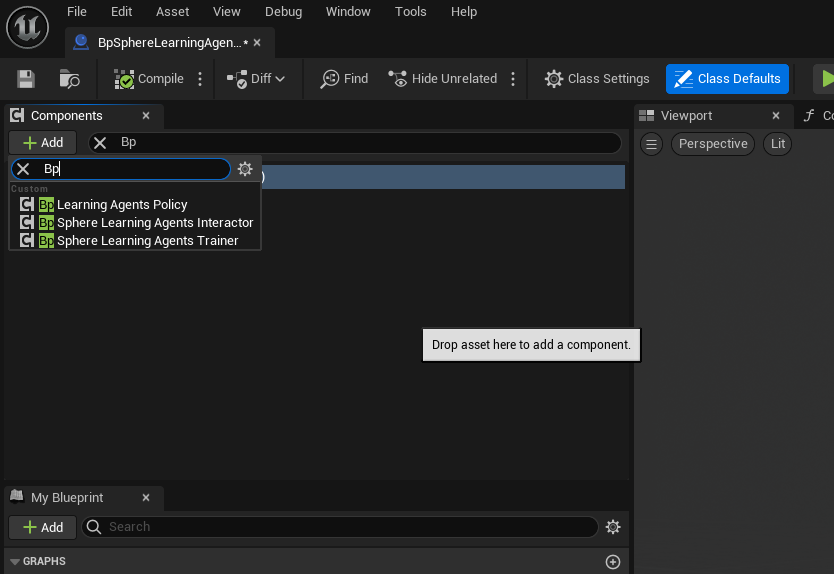
We should obtain.
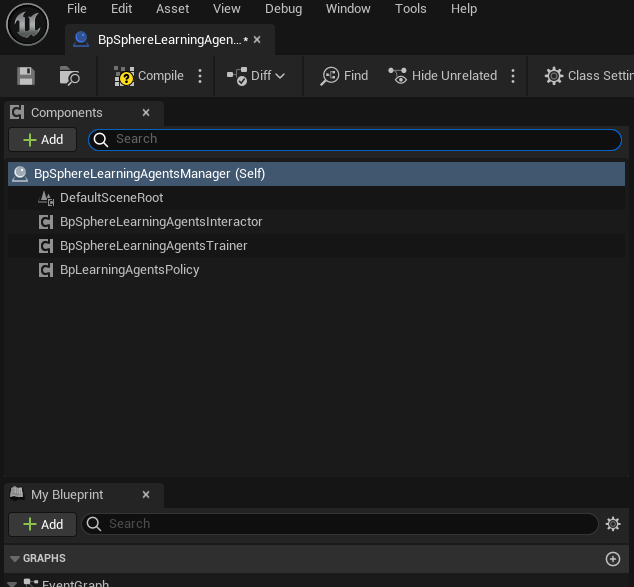
Change the tick interval to 0.01 inside the details pane and set the Max Agent Num to 32.
Changing the tick will query the policy at a constant interval time.
Create a new game mode and configure as follow.
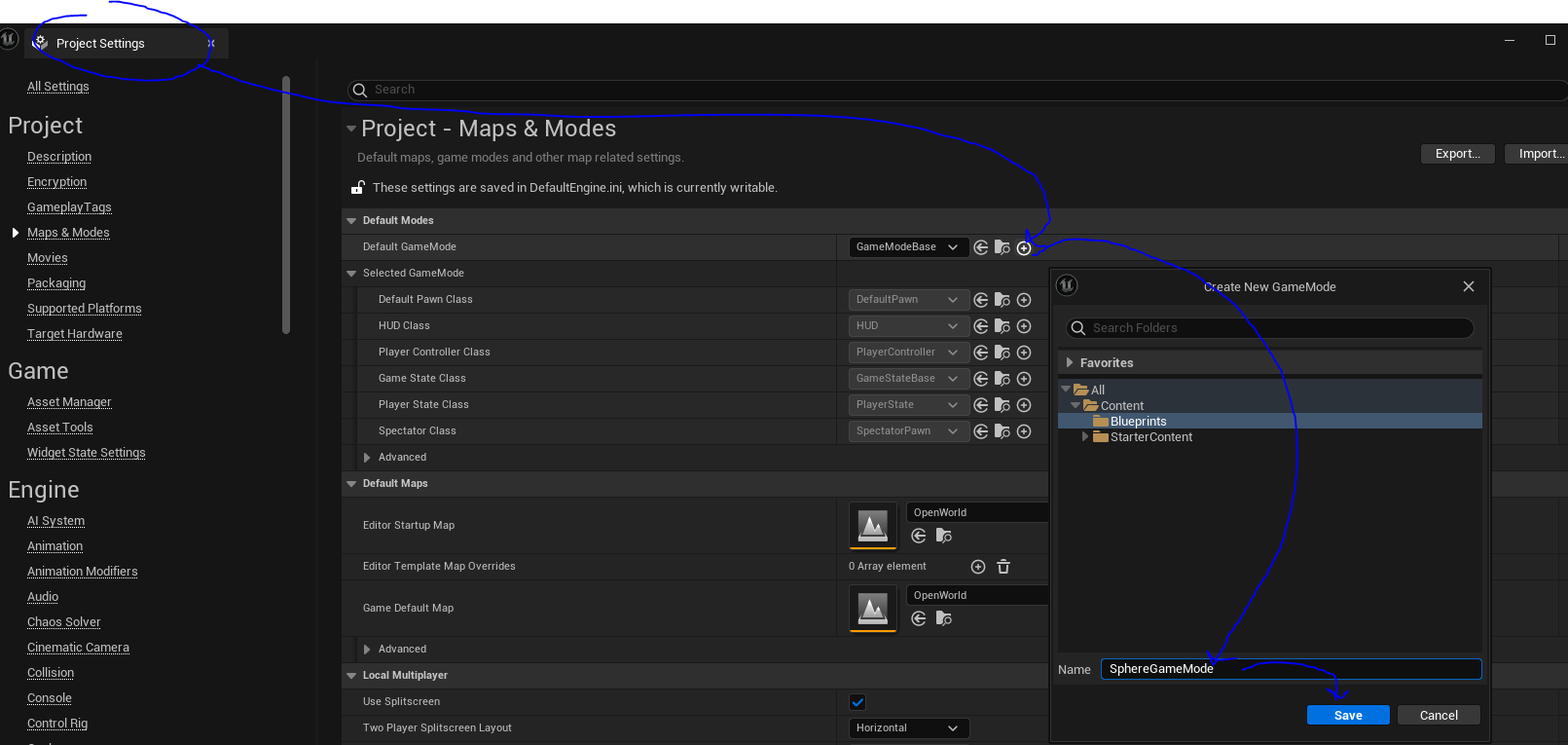
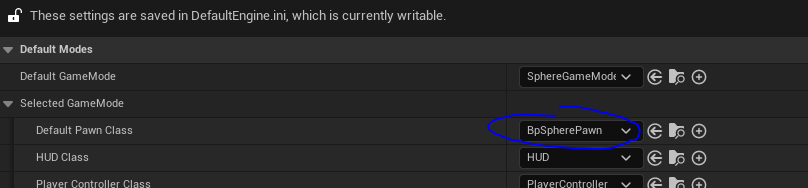
Change the default pawn class to the BpSpherePawn.
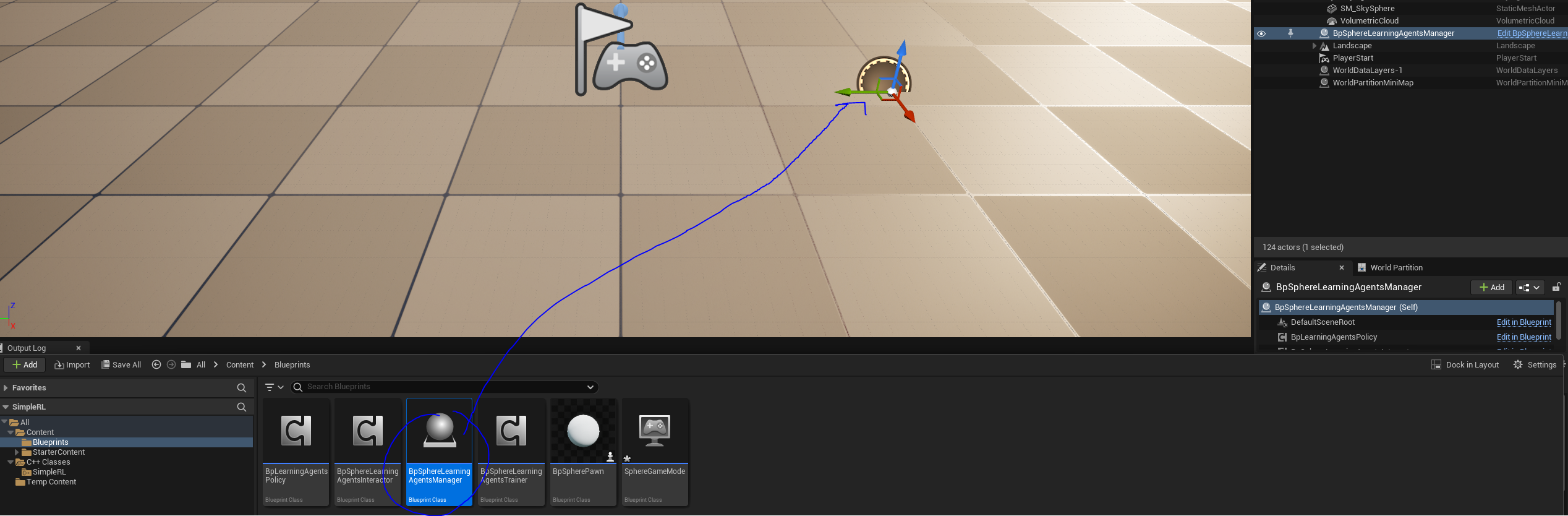
Drag the BpSphereLearningAgentsManager to the scene.
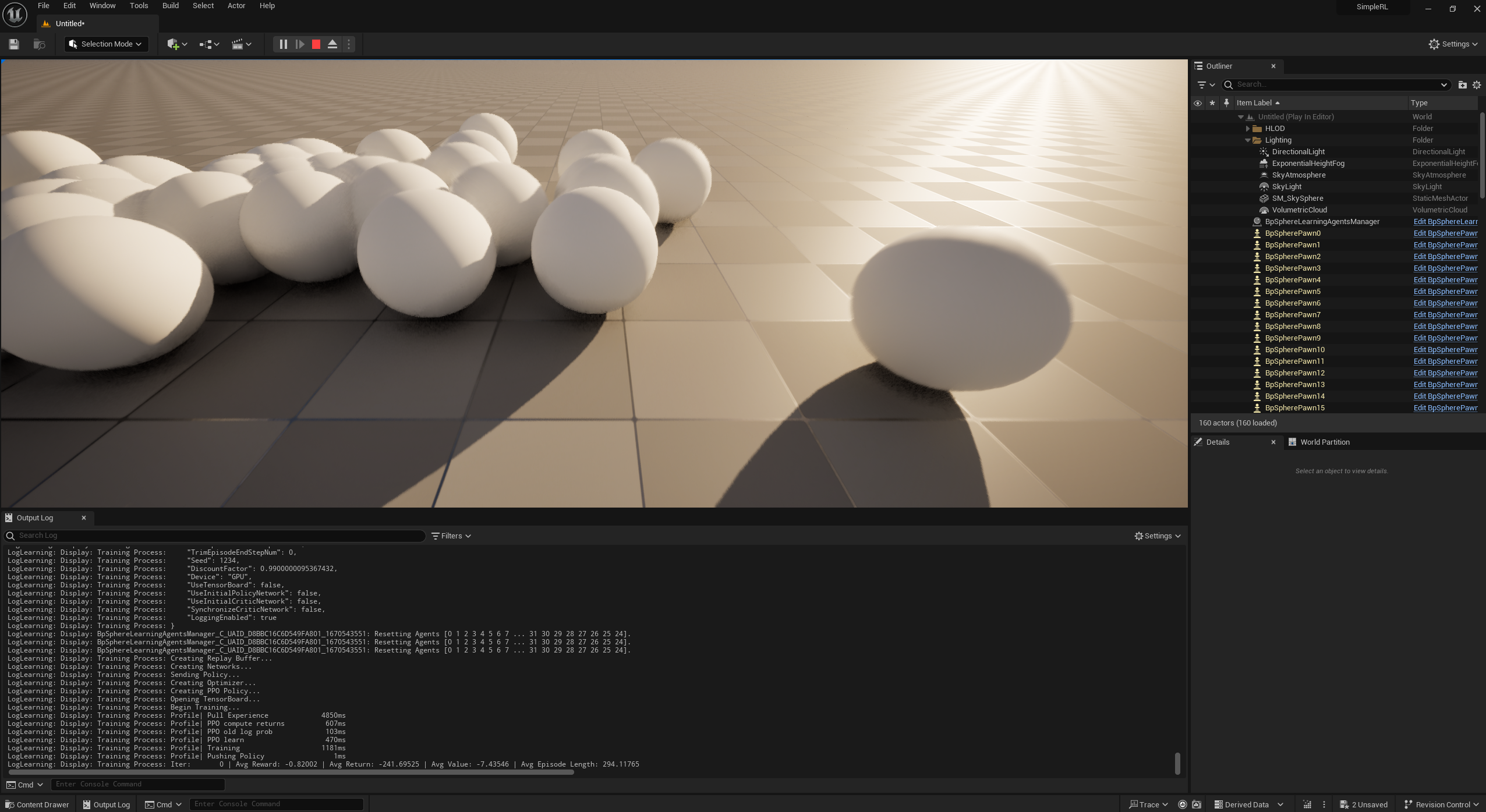
At this point if you hit play. The training will start.
When 2000 iterations completed (about 5 minutes), the training is over and we trained policy is just played all the time.
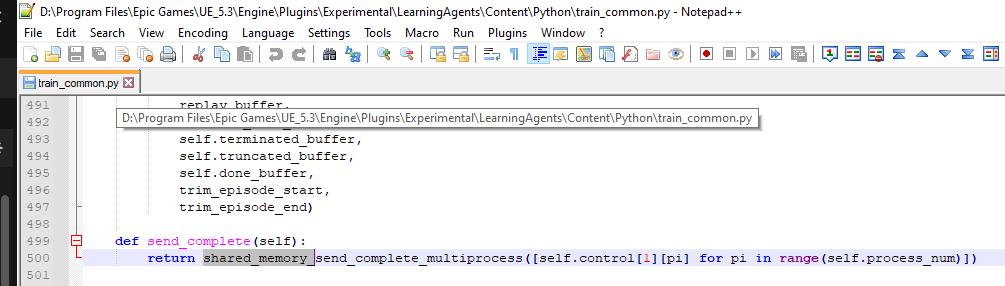
Note: if you have a python error when training is completed you can try this fix.
Rename send_complete_multiprocess to shared_memory_send_complete_multiprocess for the send_complete function inside train_common.py (the path varies depending where you installed UE5.3)
Video of the training
Contact me on: https://www.linkedin.com/in/anthony-frezzato/